Vision-Language Model (VLM): Semantic AI for Live Detection and Archive Search
AxxonSoft Vision-Language Model (VLM) adds a semantic AI layer to video management software. Instead of relying only on predefined detector logic, Axxon One can match natural-language descriptions to live and recorded video content.
With Meta-Detector VLM for real-time semantic detection and Meta-Search VLM for archive retrieval, users can describe what they need in plain English and find relevant video by meaning. This helps unify monitoring and investigation inside one AI-powered workflow.
Why Vision-Language Models Matter in Video Analytics
Traditional video analytics is highly effective when the system knows in advance what to detect. It works well for defined object classes, known rules, and structured event logic. But real-world security scenarios are often more contextual: a person climbing a fence, a package left near an entrance, or a vehicle stopped in an unusual place.
A Vision-Language Model helps bridge the gap between human descriptions and machine-readable video content. Instead of forcing operators to translate every need into detector logic, a VLM makes it possible to search and detect using natural-language descriptions of scenes, objects, actions, and context.
Meta-Detector VLM
Brings semantic detection to live video streams. Users can define a natural-language description of the scene they want to detect, and the system evaluates incoming video against that condition in real time.
Meta-Search VLM
Brings semantic retrieval to recorded video. Users can search archived footage using a description of the scene itself and retrieve the closest matches based on stored metadata.
Together, these capabilities form the foundation of the AxxonSoft VLM Pack: a semantic AI layer that helps video systems move beyond predefined detection toward searchable visual meaning.

Real-Time Semantic Detection
Meta-Detector VLM is designed for live video analysis. Instead of configuring a dedicated rule for every possible situation, users can define a scene in natural language and let the system identify matching frames in real time.
This makes it possible to work with more open-ended visual concepts that combine objects, attributes, actions, and scene context.
Examples of semantic detection may include:
• Person climbing a fence
• Person wearing pink
• Running human
• Human and dog
• Package left at the entrance
• White car at a crosswalk top view
This approach is especially useful for detecting complex visual patterns that are difficult or impractical to define with conventional rules or dedicated detectors.
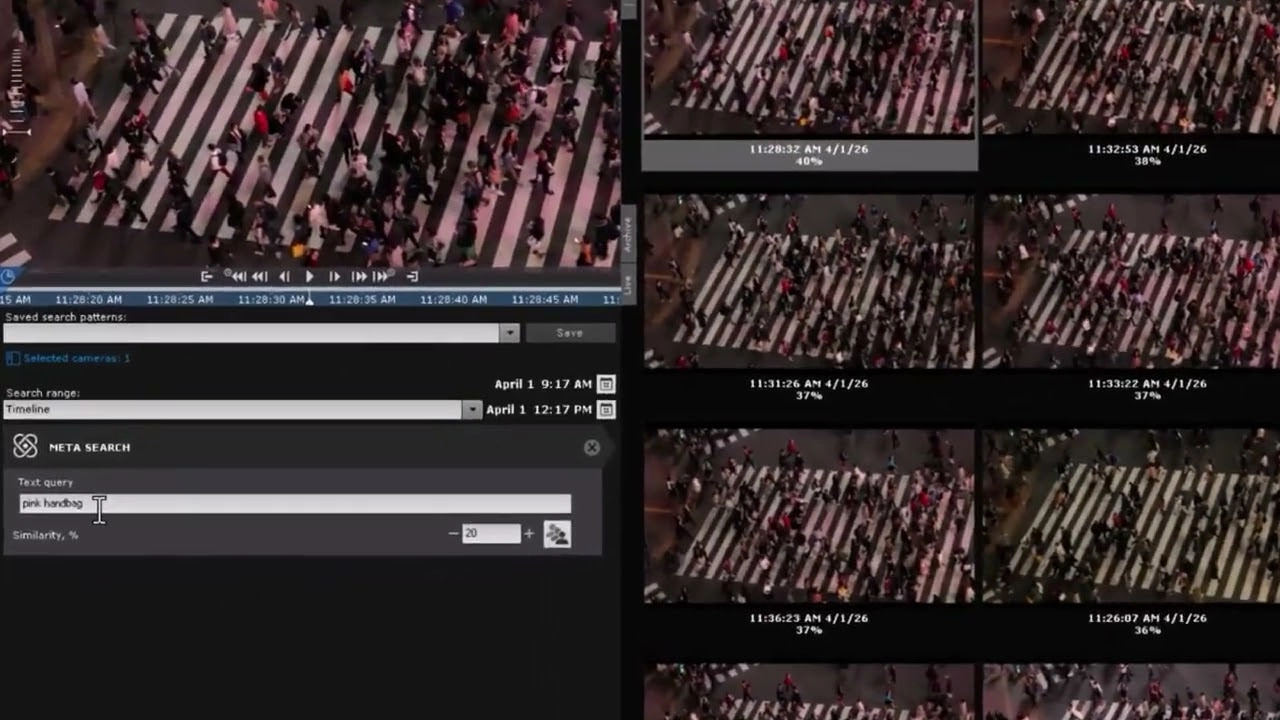
Archive-Native Semantic Retrieval
Meta-Search VLM extends the same semantic logic into recorded video. Instead of asking whether a configured detector fired, users can search the archive using a description of the scene they want to find.
This changes the archive from a collection of timestamps, events, and filters into a searchable semantic resource. Investigators can locate relevant video fragments even when they do not know the exact time of the incident or when no dedicated detector was configured in advance.
Meta-Search VLM is especially valuable for retrospective investigation, faster event localization, and more flexible forensic workflows across large video archives.
.
Why Semantic Video Search Matters
Semantic video search is becoming one of the most important directions in AI video analytics because many investigations begin with incomplete information. Operators may not know the exact timestamp or event type. They may only know what they are trying to find: a person in dark clothing near an entrance, a vehicle stopped by a gate, or someone running through a parking area.
A VLM-powered system helps turn that human description into a ranked set of candidate video fragments. This does not replace classical analytics such as motion detection, object tracking, face recognition, or license plate recognition. Instead, it adds another layer of semantic flexibility that helps users work more naturally with video.
VLM Built for Enterprise Video Management
Vision-Language Models are most valuable when they work inside real video management workflows, not as standalone AI tools. In Axxon One, VLM capabilities support both live detection and archive search within a broader security environment that includes video archives, user permissions, evidence handling, exports, and enterprise administration.
To see how this approach changes the role of AI in modern video surveillance, read our article on Vision-Language Models in Video Management Systems and explore how Axxon One turns video into searchable meaning.
Read the articleFrom Video Analytics to Searchable Meaning
The next generation of video analytics will not be defined only by more detector classes. It will be defined by how naturally users can ask questions of video.
AxxonSoft Vision-Language Model (VLM) represents that shift inside Axxon One. With Meta-Detector VLM for live semantic detection and Meta-Search VLM for archive-native retrieval, video becomes easier to interpret, easier to investigate, and easier to search by meaning.
Explore Axxon One 3.0